УДК 681.3
Д.В. Ландэ, С.М. Брайчевский
Определение тематической направленности запросов путем анализа наборов рейтинговых источников
1. Ситуация, сложившаяся сегодня в области сетевых информационных ресурсов, обладает рядом специфических аспектов, требующих известного переосмысления сформировавшихся за последние годы подходов. К числу таких аспектов относится, в частности, фактор интенсивного развития систем обработки больших текстовых массивов на фоне быстрого, по-видимому, экспоненциального, роста объемов информации, представленной в сетях. Вместе с тем, несомненно, в сетевом информационном пространстве существуют секторы, обладающие удивительным постоянством, примером которых могут служить web-сайты информационных агентств: ежедневно они предоставляют посетителям определенное количество сообщений, причем примерно одинакового объема. При этом материалы, в зависимости от текущей ситуации, могут варьироваться и ранжироваться по актуальности и содержанию. По-видимому, подобный режим подачи данных тесно связан с природой процессов сбора и обработки информации, общих для многих медийных средств.
В связи с этим, естественным выглядит разделение сетевого информационного пространства на две части и, соответственно, ввести понятия стационарных и нестационарных информационных потоков. При этом особый интерес вызывают именно стационарные потоки, удовлетворяющие следующим условиям:
- средняя плотность потока информации постоянна;
- изменения в распределении сообщений по основным параметрам в основном определяется изменениями внешнего контекста.
Поскольку с понятием информационных потоков тесно связано понятие источников, имеет смысл говорить также о стационарных и нестационарных источниках информации. Соответственно, интенсивный рост объемов сетевой информации может быть объяснен сочетанием трех факторов:
- увеличение количества стационарных источников;
- увеличение скорости генерирования информации нестационарными источниками;
- накопление ретроспективной информации на фоне неразвитых средств ее утилизации (архивирования).
Следует отметить, что приведенное понятие стационарности в определенной мере является условным, поскольку реальные источники в силу тех или иных причин могут прекращать свое существование. Однако всегда можно говорить о стационарности в локальном временном интервале.
В этой работе представлены полученные авторами результаты, относящиеся к задаче вычисления тематической направленности запросов пользователей к информационно-поисковой системе, которые базируются на анализе корреляций стационарных источников сетевой информации, соответствующих релевантным документам.
2. Одним из наиболее интересных аспектов сетевого информационного пространства, по мнению авторов, является распределение его элементов по тематическим группам, проявляющееся, в частности, в наличии характерных корреляций, которые могут быть выявлены путем анализа больших объемов данных. Именно такие корреляции и могут стать мощным инструментом структуризации сетевых информационных потоков.
В последнее время для структуризации документальных данных применяется преимущественно два качественно различных метода: рубрикация (тематическая классификация) и кластеризация. Напомним, в чем заключается различие между ними. Рубрикация предполагает распределение документов по группам, ассоциированным с осмысленными рубриками, принадлежащими некоторому заданному заранее набору. Кластеризация же заключается в группировке документов на основании их внутреннего подобия.
Однако существует еще один способ структуризации документальных потоков, который занимает в определенном смысле промежуточное место между рубрикацией и кластеризацией. Это построение с помощью информационно-поисковых систем наборов документов, релевантных определенным запросам. Действительно, запрос представляет собой нечто внешнее по отношению к полному набору документов, однако отбираются документы на основании подобия, обусловленного формальной релевантностью. В случае использования запросов может возникнуть два предельных случая. Если запрос фиксирует полный комплекс характеристик, отвечающих определенной рубрике, имеем рубрикацию, если же запрос фиксирует некоторые формальные параметры документа, то, фактически, имеем кластеризацию.
Таким образом, варьируя объем и структуру запроса, можно получить достаточно гибкий и эффективный метод группировки документов с преобладанием свойств, присущих либо рубрикации, либо кластеризации.
Особый интерес представляет исследование корреляций между распределениями классической рубрикации (поскольку она предоставляет в распоряжение устойчивое распределение документов по очерченным комплексам осмысленных характеристик) и аналогичных распределений кластеризации, построенной по заданным пользователями запросам.
В предлагаемой работе исследовалось локальное во времени распределение источников, соответствующих определенным тематическим запросам. Локальность во времени связанна с тем, что абсолютно стационарные источники - понятие скорее абстрактное.
3. В качестве основы для приведенной ниже модели использовалась система контент-мониторинга InfoStream, разработанная в Информационном центре "ЭЛВИСТИ" (ElVisti). Система InfoStream применяется для решения задач автоматизированного сбора новостной информации с открытых web-сайтов, ее систематизации и обеспечения доступа к ней в поисковых режимах. Эта система в настоящее время охватывает порядка 2000 стабильных источников информации - более 30000 уникальных новостных сообщений в сутки. На определенном этапе заполнения информационных фондов системы понадобился механизм уточнения запросов, доступный не только профессионалам, но и простым пользователям.
Исследования проводились с помощью набора инструментальных средств системы InfoStream, обеспечивающих построение, так называемого, информационного портрета, содержащего, помимо прочих, такой параметр, как "Источники" (Рис. 1). Информационный портрет - это адаптивный механизм уточнения запросов, который строится после того, как пользователь введет запрос либо активизирует режим поиска по определенной тематической рубрике. Однако он также представляет собой достаточно универсальный инструмент для изучения характеристик различных документальных выборок.
В рамках моделирования для некоторой фиксированной тематической рубрики определялся набор наиболее рейтинговых источников - информационных web-сайтов, наиболее часто публикующих информацию по данной тематике в течение определенного периода времени, к примеру, недели.

Рис. 1. Список наиболее рейтинговых источников по рубрике "Банковская деятельность"
Построенный таким образом набор данных использовался далее как эталонный. При этом полученные "сырые" данные ранжировались по 10-бальной шкале (т. е., каждому источнику в зависимости от количества релевантных рубрике документов из этого источника, присваивался нормализованный ранг в интервале от 1 до 10). В описываемом ниже примере использовались источники, соответствующие рубрике "Компьютеры", список которых приведен в Табл. 1. Точки, соответствующие этим источникам изображались на графиках символами "*" (Рис. 2-4.).
Для вычисления корреляций запросов и тематической рубрики, аналогичным образом на основании информационного портрета строились распределения рангов источников, соответствующих запросам пользователей. Рассматривалось множество наиболее рейтинговых источников, соответствующих запросам. В случае если рейтинговый для рубрики источник не входил в список рейтинговых источников запроса, то его рангу приписывалось значение 20 (что в два раза превышает реальный максимальный ранг). Ранги источников, соответствующих запросам пользователей, на графиках представлены точками.
На Рис. 2. приведен гипотетический случай, заключающийся в том, что источники, соответствующие запросу пользователя, абсолютно не коррелируют с источниками основной темы.
На Рис. 3. и 4. приведены примеры сравнения "через призму источников" тематической рубрики "Компьютеры" с пользовательскими запросами "процессоры" и "мобильные телефоны". Отклонение запроса от тематики вычислялось по формуле:
^S=1/N * Summa |^R|
где ^S - линейное отклонение (разброс) источников, N - количество источников (в исследуемом случае 50), ^R - разность рангов источника по основной теме (рубрике) и запросу пользователя.
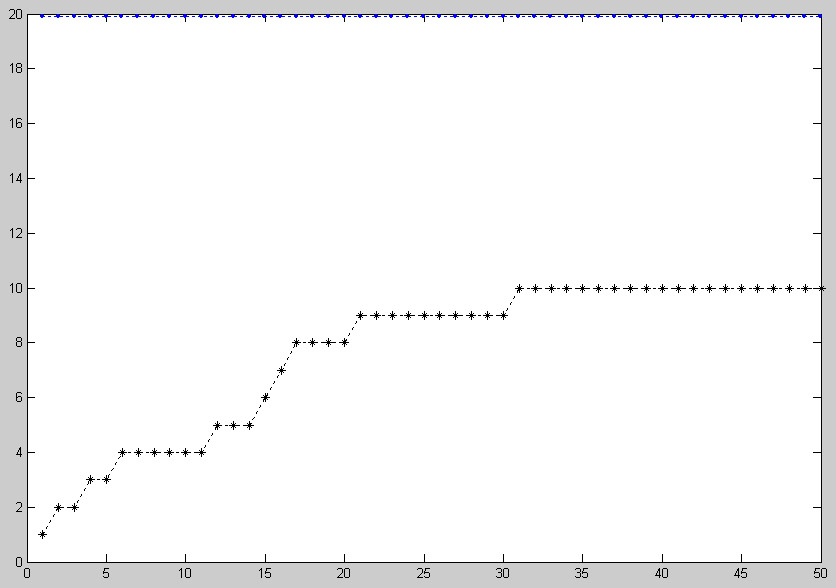
Рис. 2. Основная тема - рубрика "Компьютеры", с ней
сравнивается некоррелирующий по источникам запрос. ^S = 12.30
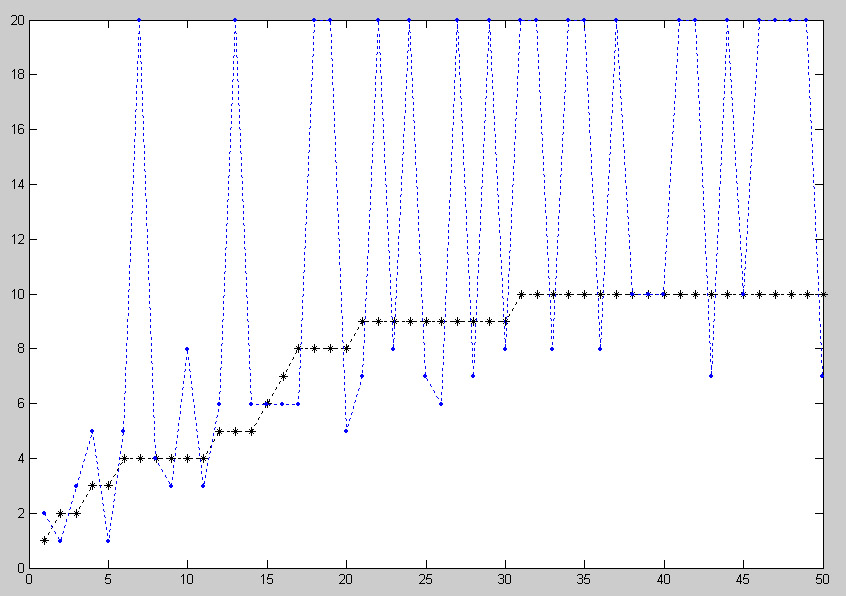
Рис. 3. Основная тема - рубрика "Компьютеры", с ней
сравнивается результаты запроса "процессоры". ^S = 5.24
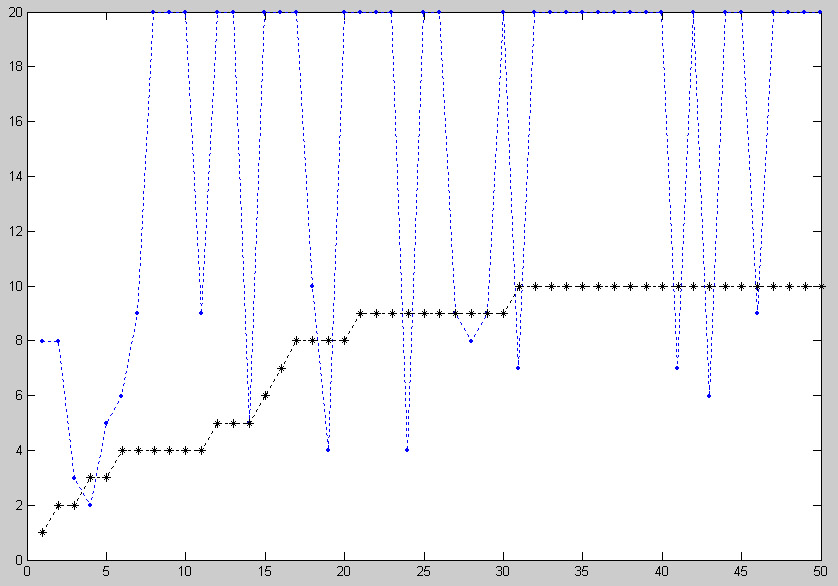
Рис. 4. Основная тема - рубрика "Компьютеры", с ней сравнивается результаты запроса "мобильные телефоны".
^S = 8.14
Из приведенных результатов с очевидностью следует, что "процессоры" значительно ближе по списку источников к основной теме, чем "мобильные телефоны".
Табл.1. 50 рейтинговых источников, соответствующих рубрике "компьютеры"
| Источники (количество документов) | Ранг | Источники (количество документов) | Ранг |
|
iXBT (30)
Россия-Он-Лайн (22) @Astera (20) RAMBLER (15) Компьюлента (14) CNews.ru (11) ПРАЙМ-ТАСС (11) iTware (11) Инфо-Бизнес (11) TUT.BY (10) 3DNews.RU (10) Tom's Hardware Guide (8) ФЦП "Электронная Россия" (7) Новости@MAIL.RU (7) ComputerWorld/Украина (6) Новости мира мобильных компьютеров (5) PCWEEK/RE ONLINE (4) Издательский дом "Коммерсантъ" (4) Sostav.ru (4) ITC online (4) Yтро (3) Эксперт-центр (3) Независимая газета (3) Альянс Медиа (3) CITFORUM.RU (3) |
1
2 2 3 3 4 4 4 4 4 4 5 5 5 6 7 8 8 8 8 9 9 9 9 9 |
HPC.ru (3)
Пробуем.ру (3) Подробности (3) VLASTI.NET (3) ZDNet (3) РИА "Новости" (2) Казинформ (2) Електронні Вісті (2) Журнал "ИТОГИ" (2) Еженедельник "Аптека" (2) DELFI (2) Портал "2000" (2) HackZona (2) Lenta.Ru (2) Computer Crime Research Center (2) NEWSRU.com (2) UA TODAY (2) KM-Новости (2) Журнал "Компьютеры+Программы" (2) AllExpo.ru (2) INLINE.RU (2) Портал "ИСРАЛЕНД" (2) Время новостей (2) ГУДОК.РУ (2) DORE.RU (2) |
9
9 9 9 9 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 |
Таким образом, получена возможность оценки тематической близости документальных массивов по характеристикам, не заданным изначально при построении собственно набора рубрик. При этом подобный анализ может проводиться независимо от использовавшихся ранее методов рубрикации.
Также следует отметить как несомненное достоинство методики простоту и наглядность интерпретации конечных результатов, связанную, в том числе, и с компактностью их представления.
4. Итак, мы видим, что приведенная методика вычисления тематической близости оказалась достаточно эффективной, в частности, для систем интеграции новостей, где количество источников ограничено (например, в настоящее время системой InfoStream охватывается порядка 2000 источников). Эта методика менее затратная и более подходит для интерактивных систем, чем такой достаточно часто применяемый метод, как анализ корреляции термов. Эффективность вычислений, кроме того, может быть повышена обучением системы - перечень рейтинговых источников, соответствующих рубрикам меняется не так уж и часто.
В заключение приведем две области практического применения приведенной методики - это контекстная реклама и развитие тематического рубрикатора. В нашем случае, если реклама привязана, например, к рубрике "Компьютеры", то ее имеет смысл демонстрировать и по запросу "процессоры". С другой стороны, если линейный разброс источников какого-либо запроса с источниками всех рубрик пороговый, то имеет смысл говорить о расширении рубрикатора - порождении новой рубрики.
Список литературы
1. Григорьев А.Н., Ландэ Д.В. Адаптивный интерфейс уточнения запросов к системе контент-мониторинга InfoStream/ Труды международной конференции "Диалог'2005", с. 109-111
2. Ландэ Д.В. Поиск знаний в Internet. Профессиональная работа - М.: "Вильямс", 2005. - 272 с.
Реферат
УДК 681.3
Определение тематической направленности запросов путем анализа наборов рейтинговых источников / Д.В. Ландэ, С.М. Брайчевский // Открытые информационные и компьютерные информационные технологии. - Харьков: НАКУ "ХАИ", 2006. - Вып. 29. - С. 169-174
Представлен подход к решению задачи вычисления тематической направленности запросов пользователей к информационно-поисковой системе, базирующийся на анализе корреляций стационарных источников сетевой информации, соответствующих релевантным документам. Описана методика оценки тематической близости документальных массивов по характеристикам, не заданным изначально при классификации.
Ил. 4. Библиогр.: 2 назв.
Наведено підхід до вирішення завдання обчислення тематичної спрямованості запитів користувачів до інформаційно-пошукової системи, який базується на аналізі кореляцій стаціонарних джерел мережної інформації, що відповідають релевантним документам. Описано методику оцінки тематичної близькості документальних масивів за показниками, які не задано заздалегідь при класифікації.
Іл. 4. Бібліогр.: 2 назв