| УДК 681.3 | Д.В. Ландэ |
Сканер системы контент-мониторинга InfoStream
Пользователей Internet уже давно не интересуют информационные ресурсы сами по себе. Востребованной оказывается информация по определенным тематикам, видовым или временным срезам [1]. Именно последнему аспекту - новостной информации из Интернет, особенностям ее сбора в системе контент- мониторинга InfoStream® посвящена данная публикация.
Принцип работы роботов традиционных сетевых информационно-поисковых систем общеизвестен [2]. Стартуя с базового набора адресов web-сайтов, они сканируют содержание web-страниц, индексируют его, вычисляют адреса следующих web-сайтов, на которые указывают гиперссылки, после чего итеративно переходят по этим адресам. Так продолжается до тех пор, пока процесс не прервется в соответствии с некоторыми установленными условиями. При этом осмысленной обработке содержания отдельных web-страниц уделяется не очень много внимания - чаще всего выделяются МЕТА-тэги и элементы заголовков, такие, как дата или кодировка. Недостаточно внимания уделяется и обеспечению полноты охвата ресурсов, а также оперативности сканирования (при 20-миллиардном документальном фонде WWW достижение этих показателей весьма проблематично).
Для решения задач автоматизированного сбора новостной информации с web-сайтов, ее обработки, систематизации и обеспечения доступа к ней в Информационном центре "ЭЛВИСТИ" разработана система контент-мониторига InfoStream. Несмотря на то, что эта система обрабатывает информацию с ограниченного количества web-сайтов (действительно необходимых, доступных, надежных, проверенных экспертами), по сравнению с традиционными подходами система InfoStream обеспечивает ряд преимуществ:
- предоставление оперативного доступа пользователей к информации по мере ее появления в Internet;
- своевременное "напоминание" и "проталкивание" профильной для пользователей информации;
- обеспечение целенаправленной работы пользователей с информацией;
- обеспечение работы с контролируемым набором источников;
- надежность доставки информации, конфиденциальность.
Для всех случаев представления информации на целевых web-сайтах в системе InfoStream используется единое программное обеспечение - сканер, обеспечивающий мониторинг web-ресурсов Internet и корпоративных intranet- сетей. Сбор данных (Рис. 1) выполняется путем обхода сетевых ресурсов в соответствии с инструкциями на метаязыке системы, которые создаются экспертами.
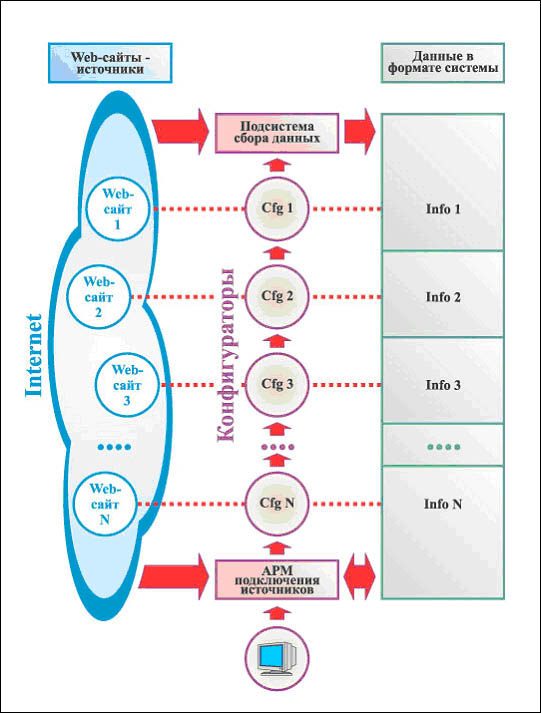
Рис.1. Процедура сбора данных
Конфигураторы сканера представляют собой совокупность сценариев на метаязыке, которые содержат алгоритмы "выхода" на информационные ресурсы, подлежащие сканированию, и инструкции по их обработке. Это означает, что конфигураторы сканера решают две основные задачи - определение пути к целевым документам и их структуры.
Соответственно в каждом конфигураторе реализуются два конфигурационных элемента - пути и структуры.
Первая строка элемента пути содержит базовый адрес (URL), с которого начинается процесс сканирования. Вторая и следующие строки - это маски адресов web-страниц, последовательное прохождение которых выводит к целевым web-страницам (Рис. 2.). В этих строках маски пишутся в соответствии со стандартами регулярных выражений (RegExp), а непосредственная адресная часть берется в скобки. При этом абсолютные адреса web-страниц вычисляются в соответствии с правилами, определенными протоколом HTTP.
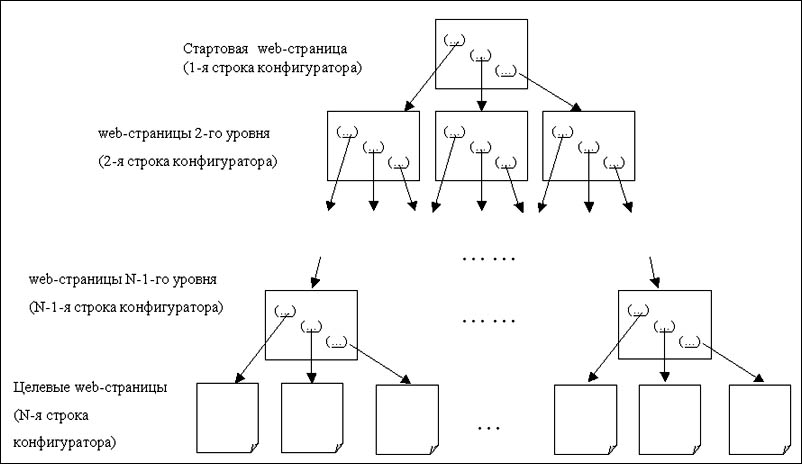
Рис. 2. Реализация "выхода" на целевые web-страницы
Вторая задача, стоящая перед сканером, заключается в выборе обязательных элементов, наиболее полно охватывающих контент web-страниц источников. Соответственно вторая компонента конфигуратора, элемент структуры, определяет информацию о сканируемых web-страницах, такую, как шаблоны начала и конца информационной части web-страниц, шаблоны, которыми начинаются и заканчиваются определенные текстовые блоки (поля), таблицы замены определенных символов и т.д.
Шаблоны, или маски, применяемые в конфигураторах сканера, это регулярные выражения (RegExp), позволяющие строить маски для выделения искомой строки из текстового (или html-) файла. При построении регулярных выражений используются следующие специальные символы: +?.*$()[]{}|\. Перед написанием специальных символов как частей искомых строк в фильтрах следует вставлять символ "\"(обратная косая черта). В шаблонах некоторые символы или последовательности символов имеют определенный смысл:
^ - начало строки;
$ - конец строки;
[...] - класс символов;
[^...] - негативный класс символов;
(...|...|...) - одна из альтернатив;
+ - элемент повторяется 1 или более раз;
? - элемент встречается 0 или 1 раз;
* - элемент встречается 0 или более раз;
{N,M} - элемент встречается минимум N и максимум M раз;
\w - алфавитно-цифровой символ и "_";
\W - неалфавитно-цифровой символ;
\s - пробел;
\S - не пробел;
\d - цифра;
\D - не цифра.
В процессе сканирования на основе конкретного конфигуратора сканер обращается к источнику и итеративно формирует последовательность URL- адресов целевых web-страниц. Каждая целевая страница может содержать одно или несколько информационных сообщений. Сканер считывает целевую web- страницу источника, выделяет текстовые блоки сообщений. Выходной поток сканера представляет собой линеаризованное содержимое web-сайта (или его раздела) в виде последовательности сообщений. Ленты, созданные с помощью определенного конфигуратора, образуют единую ленту источника.
Для решения задачи интеграции новостей, а также обеспечения доступа к ней в системах интеграции новостей широко используется формат данных RSS, что означает Really Simple Syndication, Rich Site Summary, RDF Site Summary. Смысл всех этих интерпретаций заключается в простом способе обобщения и распределения информационного наполнения web-сайтов - синдикации контента [3].
Сегодня практически все ведущие новостные сайты, "живые журналы", работающие в Internet, используют RSS в качестве инструмента оперативного представления своих обновлений. Например, сегодня экспорт в RSS осуществляют крупнейшие порталы, включая CNN, BBC News, Amazon, CNet News, MSNBC, The Register, Wired и т.д.
В настоящее время существует 7 независимых версий RSS - RSS 0.90, 0.91, 0.92, 0.93, 0.94, 1.0, 2.0. Эти версии, конечно, отличаются друг от друга, хотя все они ориентированы на один тип информации и содержат одинаковые базовые поля. При этом многие считают все версии, кроме 2.0 устаревшими и "отмененными", но это далеко не так: пока еще самой популярной является RSS 0.91. Спецификации отдельных версий формата RSS приведены на таких web-страницах:
RSS 0.90: http://www.purplepages.ie/RSS/netscape/rss0.90.html RSS 0.91: http://my.netscape.com/publish/formats/rss-spec-0.91.html RSS 0.92: http://backend.userland.com/rss092 RSS 0.93: http://backend.userland.com/rss093 RSS 1.0: http://web.resource.org/rss/1.0/ RSS 2.0: http://backend.userland.com/rss/
Все версии RSS объединяет их ориентация на один тип информации, вследствие чего они содержат общие базовые поля: основной блок данных (channel), содержащий такие атрибуты, как заглавие канала (title), ссылки (link), данные о языке сообщений (language) и логотип (image), после которых идет список самих сообщений, где в каждом пункте (item) указываются заголовок (title), краткое описание (description) и ссылка на новость (link). Кроме того, каждый RSS-файл начинается обязательными элементами xml и rss. Первый из этих элементов содержит атрибуты version (версия) и encoding (кодировка).
Среди множества необязательных элементов RSS можно назвать самые распространенные: язык (language), copyright, категория информации (category), дата и время публикации сообщения (pubDate), программа, которая использовалась для создания файла (generator), картинка, которую следует показывать наряду с текстовой информацией (image).
Кроме заголовка блока данных в формате RSS предусмотрено описание отдельных информационных элементов (item). Каждый элемент - это отдельная статья или краткая аннотация и ссылка на полную версию статьи. Канал (channel) может содержать любое количество элементов , содержащих только два обязательных вложенных: название (title) и описание (description). Кроме того, часто используются такие вложенные элементы: ссылка на первоисточник (link), категория (category), комментарий (comments) и автор (author).
Создание и модификация конфигураторов выполняется администратором с помощью специального автоматизированного рабочего места - АРМ подключения источников.
АРМ подключения источников системы InfoStream обеспечивают настройку на отдельные web-сайты с целью формирования на их основе массивов в унифицированном текстовом виде (в формате RSS) - информационных лент.
На Рис. 3. представлена стартовая страница АРМ. Вся площадь экрана разделена на четыре области. Левая верхняя область позволяет выбрать описание одного из уже включенных в систему источников или создать конфигуратор для нового web- сайта. Левая нижняя часть - это своеобразный пульт управления для просмотра содержания и структуры исследуемой web-страницы. Содержание можно просмотреть в исходном формате, в виде, интерпретированном текстовым браузером (типа Lynx), а также в виде, в котором его видит обычный пользователь (web-представление). Предусмотрена возможность просмотра и главных тэгов исследуемой страницы (заголовков, гиперссылок, специально выделенных фрагментов и др.). Вся выходная информация отображается в правом верхнем фрейме экрана. Правая нижняя часть экрана предназначена для описания маршрута выхода на целевые документы (создание конфигурационного элемента пути), которые могут быть основой построения информационных лент.
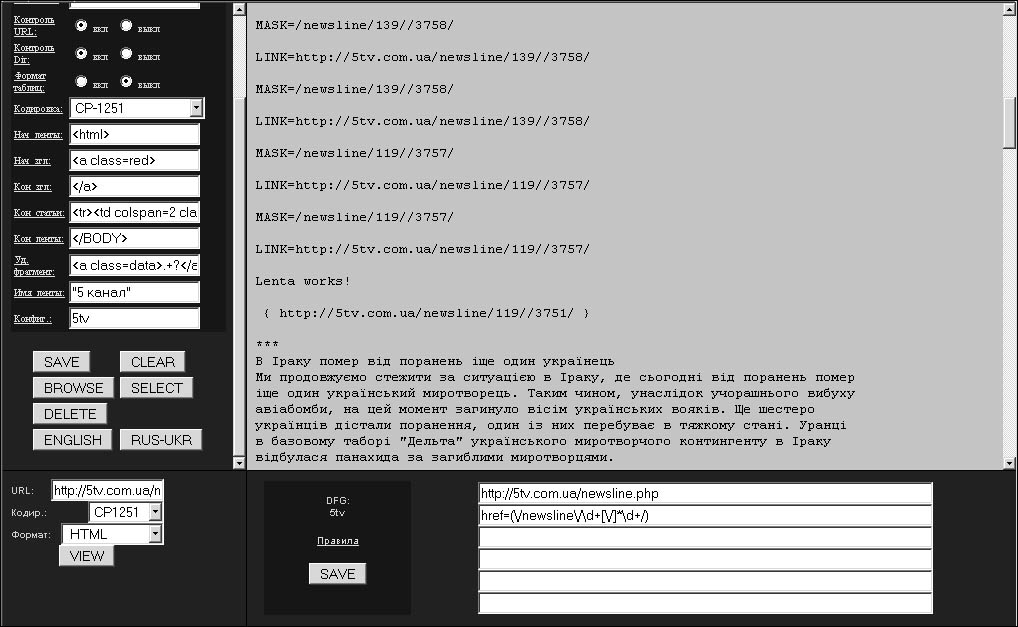
Рис. 3. Стартовая страница АРМ подключения источников
После заполнения соответствующих фреймов АРМ и сохранения в хранилище конфигуратора (путем нажатия на клавишу "SAVE") можно нажать на клавишу "BROWSE" и в левом верхнем фрейме просмотреть результаты настройки на web-ресурс. На Рис. 4. приведен пример с результатами формирования информационной ленты.
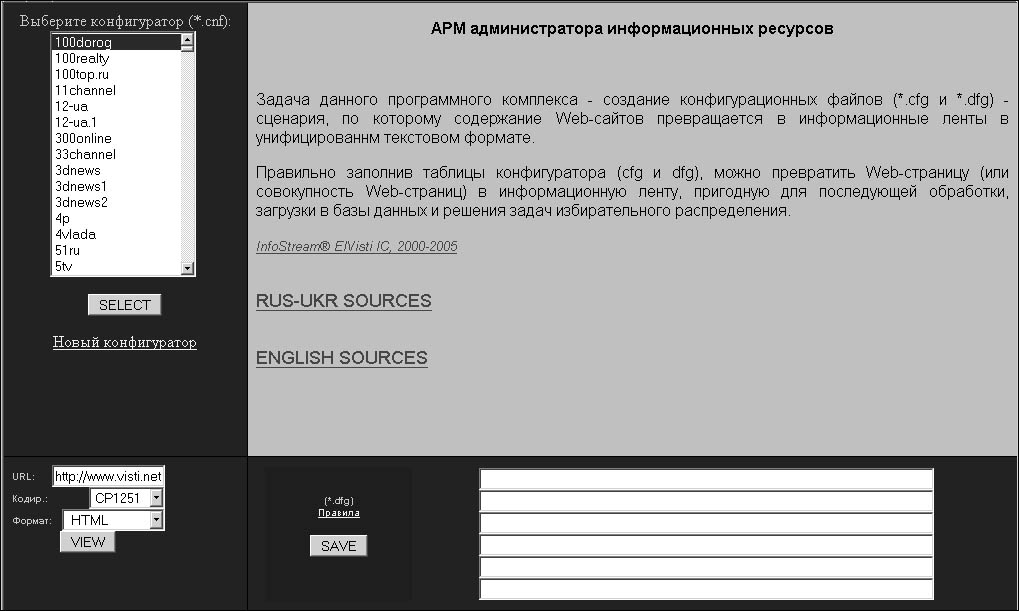
Рис.4. Формирование информационной ленты в интерфейсе АРМ
После получения информационной ленты система InfoStream переходит к следующим этапам - выявлению ключевых слов, классификации, определению языков материалов, формированию полнотекстовых баз данных [4, 5]. Однако описание этих процессов выходит за рамки настоящей публикации. Представленный программно-технологический комплекс в настоящее время в оперативном режиме реализует охват в среднем 30000 уникальных новостных сообщений в сутки из более 1500 источников. При этом оказывается важным не только доступ к оперативным новостям. Накопленная информация представляет собой уникальный ретроспективный фонд (далеко не каждый web-сайт содержит свои архивы).
Сканер системы InfoStream может быть настроен на большую часть открытых web-сайтов из Internet. Исключения составляют лишь некоторые источники, информация в которых отдается изощренными средствами Java-апплетов, а также web-сайты со специально установленной защитой. В заключение можно констатировать: чаще всего, чем содержательнее уровень web-сайта, тем выше и его технологический уровень, тем успешнее реализуются корректный сбор и интеграция информации.
Список литературы
- Григорьев А.Н., Ландэ Д.В. New media - новая информационная среда // "Сети и телекоммуникации", -2000, - 4, С. 18 - 22
- Ландэ Д.В. Поисковые системы: поле боя - семантика // "Телеком", -2004, - 4, С. 44 - 50
- Ландэ Д.В, Морозов А.Ю. Новостной Интернет. // "Телеком", -2005, - 1-2, С. 58-62
- Ландэ Д.В. Добыча знаний // "Телеком", -2004, - 1-2, С. 36-42
- Ландэ Д.В. Поиск знаний в Internet. Профессиональная работа - М.: Изд. дом "Вильямс", 2005. - 272 с.
Реферат
УДК 681.3
Сканер системы континент-мониторинга InfoStream / Д.В. Ландэ // Открытые информационные и компьютерные интегрированные технологии. - Харьков: НАКУ "ХАИ", 2005. - Вып. 28. - С. 53 - 58
Для автоматизированного сбора новостной информации с web-сайтов, ее обработки, систематизации и обеспечения доступа к ней в Информационном центре "ЭЛВИСТИ" разработана система контент-мониторинга InfoStream. Для всех случаев представления информации на целевых web-сайтах (сегодня их - свыше 1500) в системе InfoStream используется единое программное обеспечение - сканер, обеспечивающий мониторинг web-ресурсов путем обхода сетевых ресурсов в соответствии с заданными инструкциями на метаязыке системы.
Ил. 4. Библиогр.: 5 назв.
З метою автоматизованого збирання новинно╖ ╕нформац╕╖ з web-сайт╕в, ╖╖ обробки, систематизац╕╖ та забезпечення доступу до не╖ у ╤нформац╕йному центр╕ "ЕЛВ╤СТ╤" розроблено систему контент-мон╕торингу InfoStream. Для вс╕х випадк╕в подання ╕нформац╕╖ на ц╕льових web-сайтах (на сьогодн╕ ╖х - понад 1500) в систем╕ InfoStream використову╓ться ╓дине програмне забезпечення - сканер, який забезпечу╓ мон╕торинг web-ресурс╕в шляхом обходу мережних ресурс╕в в╕дпов╕дно до заданих ╕нструкц╕й на метамов╕ системи.
╤л. 4. Б╕бл╕огр.: 5 назв