|
Вiсник державної Служби України, N 2'2002
Прийняття рішень з управління будь-якою системою, і особливо такою, як система державної служби країни, має спиратися на інформацію, яка дає комплексне уявлення про поточний стан системи і її реакцію на зовнішні збудники та організаційно-структурні перетворення. Для аналізу і оцінки стану складових системи державної служби, перелік і зміст яких наведено в [1], застосовуються дані статистичної звітності щодо корпусу державних службовців (форма N 9-ДС), одномоментні зрізи, передбачені певними нормативно-прововими і організаційно-розпорядчими документами щодо кадрового резерву, потреб у підготовці і підвищенні кваліфікації державних службовців тощо. Заходами щодо аналізу стану роботи з кадровим ресурсом державного управління є: планові перевірки відповідної сфери діяльності органів виконавчої влади; комп'ютерний облік персональних даних про осіб, що займають посади I-III категорій державних службовців; опитування консультативно-навчальні семінари із контингентом слухачів Інституту підвищення кваліфікації керівних кадрів Української Академії державного управління при Президентові України. Значною мірою вивчення роботи органів виконавчої влади в сфері державної служби пов'язане з удосконаленням нормативно-правової бази державної служби, передбаченим положенням положеннями Стратегії реформування системи державної служби в Україні, затвердженої Указом Президента України від 14 квітня 2000 року N 599. Усі ці заходи складають основу для організації і забезпечення процесу управління державною службою. Зрозуміло, що атрибути проходження державної служби як конкретною особою, так і окремим апаратом органу виконавчої влади певним чином пов'язані з якістю функціонування системи державного управління, її результативністю і, зрештою, з ефективністю діяльності органу в цілому. Розділом "Оптимізація управління державною службою" зазначеної вище Стратегії передбачено, зокрема, змінити протягом 2000-2004 років характер діяльності кадрових служб органів виконавчої влади, зосередивши їх увагу на аналітичній і організаційній роботі з кадрового менеджменту, аналізі ефективності відповідного органу, його структурних підрозділів, професійній діяльності кожного державного службовця, прогнозуванні розвитку персоналу, плануванні кар'єри державних службовців, забезпеченні їх навчання та моніторингу ефективності роботи. Таким чином, серед напрямів удосконалення кадрової роботи ми бачимо пряме посилання на необхідність запровадження потужного сучасного інструменту для отримання "зворотного зв'язку" - моніторингу діяльності як апарату органу в цілому, так і його окремих працівників. Необхідність запровадження нових механізмів дослідження в сфері державної служби викликала потребу у створенні відповідних механізмів: методики і засобів моніторингу діяльності органів виконавчої влади. Побудову зазначених механізмів було передбачено заходами щодо реалізації стратегії реформування системи державної служби в Україні на 2000-2001 роки, затвердженими Указом Президента України від 26 липня 2000 року N 925. Дослідження і відповідні розробки було виконано в межах програми удосконалення єдиної державної комп'ютерної системи "Кадри" та розділу "Інформатизація стратегічних напрямів державності, безпеки та оборони" Національної програми інформатизації. Розглядаючи можливі напрями дослідження у сфері моніторингу діяльності, було запропоновано виходити з таких масивів даних, які або існують, або можуть бути отримані в межах чинного правового поля та перспективних планів його розвитку. З урахуванням встановленого обмеження розглянуто і реалізовано підходи до аналізу діяльності органів виконавчої влади на основі даних: статистичної звітності, яка вже впроваджена; функціонального дослідження діяльності органу з урахуванням досвіду роботи, проведеної органами державної влади на виконання Указів Президента України від 11 лютого 2000 року N 208 "Про підвищення ефективності системи державної служби" та від 29 травня 2001 року N 345 "Про чергові заходи щодо дальшого здійснення адміністративної реформи в Україні"; щодо проблемних питань, які висвітлюються в документах, листах, зверненнях, що надходять до Головдержслужби України; матеріалів засобів масової інформації (ЗМІ) з питань діяльності органів виконавчої влади. Цю статтю присвячено розгляду особливостей організації моніторингу діяльності органів виконавчої влади, інформацію про які подано в електронних ЗМІ, а саме в Інтернет-просторі. Інтернет сьогодні - це медіасередовище, в якому існують електронні клони звичайних ЗМІ (газет, журналів тощо) і, що найголовніше, утворено інтернет-ЗМІ (е-media), зовнішньо оформлені як інформаційні сторінки - сайти. На деяких сайтах інформація оновлюється безперервно. У цьому розумінні контент-моніторинг (від англ. content - зміст) сайта означає аналіз цого наповнення. Сьогодні контент-моніторинг інтернет-ЗМІ можна виконати тільки з урахуванням певних обмежень, адже кількість новинних повідомлень, що публікуються в мережі Інтернет в усьому світі, перевищує 1 000 000 на добу. Найбільші мережні інтегратори новин обробляють щодоби десятки тисяч повідомлень. Ситуація різкого збільшення темпів виробництва інформації обумовила виникнення низки таких проблем, як:
Аналіз і узагальнення великих динамічних інформаційних масивів, що безупинно генеруються у мережі, вимагає якісно нових підходів. Виникла необхідність створення методів моніторингу інформаційних ресурсів, тісно пов'язаних з методологією контент-аналізу. Контент-моніторинг, у нашому розумінні, це змістовний аналіз інформаційних потоків з метою одержання необхідних якісних і кількісних зрізів, що, на відміну від контент-аналізу, здійснюється постійно у часі. До теоретичних і методологічних передумов систем контент-моніторингу можна віднести появу і розвиток: теоретичних основ контент-аналізу, теорії "розкопок тексту" (Data Mining); методів математичної лінгвістики; теорії кластерного аналізу. Розроблена версія системи контент-моніторингу вирішує задачі формування тематичних інформаційних каналів, дайджестів, таблиць взаємозв'язків понять (які виявлені у споріднених публікаціях) і гістограм розподілу "вагових" значень окремих понять. Розроблено основні компоненти технології, що забезпечують:
Ця система контент-моніторингу базується на статистичних методах контент-аналізу, що останнім часом одержали розвиток в усьому світі. Так, можна відзначити досить цікаві російські проекти "Ключі від тексту" М. Г. Крейнеса, "Зброя аналітика" компанії "Інвента", проект "ВААЛ" та інші. У розробленому проекті системи контент-моніторингу, який реалізовано Інформаційним центром "Електронні вісті", побудова таблиць взаємозв'язків і гістограм розподілу "вагових" значень понять базується на мовних засобах інформаційно-пошукової системи (ІПС), а також методах статистики і кластерного аналізу. Мова визначення семантичної наповненості понять будується на основі мови запитів ІПС. Запит для визначення семантики поняття складається з двох частин - змістовної частини (наприклад, ключових слів і словосполучень, що ідентифікуються як сфера діяльності певного органу влади) і якісної ознаки (наприклад, "ставлення", "враження", "клімат", "вплив" тощо). При цьому характеристика якісної ознаки ("вдало", "відмінно", "недостатньо" тощо) контекстуально пов'язується мовою із певною якісною ознакою (варіант прив'язки подано в таблиці).  Істотним при визначенні семантики поняття є контекстуальна близькість у документі змістовної частини і якісної ознаки. Як показує практика, це рішення в більшості випадків є досить ефективним. Очевидно, що для визначення семантики понять не підходить поєднання двох частин запиту звичайним оператором "І" (AND), що забезпечує пошук у межах документа. Необхідною умовою релевантності результату є використання варіанта оператора кон'юнкції, що забезпечує пошук у межах одного абзацу або одного речення. Для реалізації цих можливостей документ вхідного потоку розбивається на фрагменти (абзаци або речення), що потім самі розглядаються як окремі документи і класифікуються засобами ІПС. Після завершення процесу автоматичної класифікації з фрагментів знову складаються документи, яким приписуються згруповані класифікаційні ознаки. Таблиця взаємозв'язків понять, яка будується як статистичний звіт, що відбиває близькість (спільну присутність у публікаціях) окремих понять реального світу, - це симетрична матриця A={aij}, де aij - коефіцієнти взаємозв'язку пари понять i та j. Коефіцієнт aii відповідає кількості документів вхідного інформаційного потоку, що включають поняття (чи терміни словосполучення, представлені мовою запитів, що відповідають поняттю) i, а коефіцієнт aij - кількості документів у вхідному потоці, що водночас відповідають поняттям i та j. При цьому для перекомпоновки понять з метою виявлення блоків - множин найбільш взаємозалежних понять - застосовується алгоритм кластерного аналізу. Наприклад, для виділення двох таких блоків необхідно виділити два поняття-полюси (наприклад, які відповідають індексам k і l), найбільш тісно пов'язаних з іншими поняттями, але найменш пов'язаних між собою. Формально ці умови можна записати у такий спосіб: S aik - akk --> max S ail - all --> max akl --> min, k =\= l Інші поняття (наприклад, поняття і) відносяться до блоку k, якщо aik > ail. Інакше, поняття і буде віднесено до блоку l. Для відображення таблиці взаємозв'язків понять окремі елементи матриці А подаються різними відтінками сірого кольору (залежно від значень коефіцієнтів взаємозв'язку aij), як це наведено на рис.1. 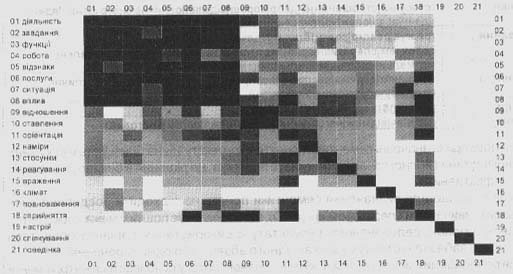
Рис.1. Діаграма взаємозв'язку понять (полюс: діяльність) Оброблено 123 статті На рис.2 подано гістограму розподілу понять, отриману на основі аналізу характеристик діяльності органу. 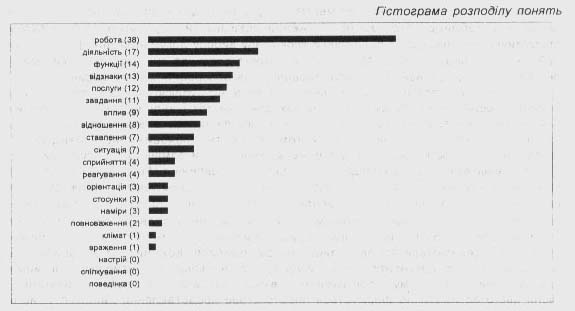 Ще одна базова процедура системи контент-моніторингу - це автоматичне формування дайджестів. Для дайджесту відбираються документи, у яких найбільш явно відбиті тенденції усього вхідного потоку. Отже, такі дайджести повинні найбільшою мірою відповідати інформаційним потребам користувача, за запитом якого формується цей вхідний інформаційний потік. Для формування дайджестів використовуються статистичні алгоритми, засновані на "ваговому" частотному підході. На першому етапі формування дайджесту на підставі слів, що входять у вхідний інформаційний потік, будується словник понять. При цьому кожному зі слів приписується деякий ваговий коефіцієнт, що визначається як результат обліку декількох складових: частоти зустрічі цього поняття, тематичного словника, визначеного на основі вхідного інформаційного потоку, "плюса-словника", що включає найбільш важливу лексику загального призначення. Для формування дайджестів послідовно виконується виділення всіх слів вхідного потоку документів і побудова з них наскрізного словникового масиву; нормалізація слів за допомогою засобів автоматичного морфологічного аналізу; сортування всіх слів словникового масиву і припис їм ваги - частоти зустрічі. Наступним кроком є вилучення зі словникового масиву незначних слів. Для цього використовуються спеціальні програмні засоби, засновані на використанні "стоп-словника". Відповідно із запитом відбувається вибір тематичного словника і наступне коригування словникового масиву з урахуванням тематичного словника - тобто коригування "ваги" окремих слів, що входять у тематичний словник. За таким самим алгоритмом відбувається коригування словникового масиву з обліком "плюс-словника". Останній крок формування словника системи полягає у виборі N (у даний час дорівнює 100) самих "вагомих" слів зі словникового масиву. Вибір документів для побудови дайджесту реалізується з урахуванням "ваги" кожного документа, що визначається як нормована за довжиною документа сума "ваги" окремих слів, що входять у цей документ. Етап вибору документів для дайджесту складається з таких кроків, як визначення "ваги" кожного документа, сортування вхідного потоку документів за "вагою", визначення смислових дублів документів за статистичним критерієм, відкидання документів, непридатних для побудови дайджестів (за допомогою таблиць "стоп-адрес" і "неприпустимих типів документів"), а також статистично змістових дублів. Останній крок етапу вибору документів для формування дайджесту полягає у виборі М (на даний момент дорівнює 10) самих "вагомих" документів з відсортованого і відфільтрованого на попередніх кроках масиву. Статистичний алгоритм визначення документів, які дублюються, із вхідного потоку полягає в обрахуванні ланцюжків ключових слів і частот їхньої зустрічі для окремих документів та наступному порівнянні між собою цих ланцюжків слів для всіх документів вхідного потоку. В існуючій версії системи кількість ключових слів у ланцюжку і коефіцієнт близькості цих ланцюжків може встановлювати адміністратор системи. Останній етап формування дайджесту полягає у виділенні з М відібраних документів найбільш значущих пропозицій і побудова з них безпосередньо тексту дайджесту. Для цього за кожним з М відібраних документів будується словник, що коригується за "плюс-словником" і тематичним словником, саме так, як і весь словник системи. Потім відкидаються пропозиції, що не відповідають емпірично обумовленим семантичним правилам, і зважуються всі пропозиції, що залишилися. Кожний з М відібраних на попередньому етапі документів присутній у дайджесті не більш ніж К найбільш вагомими пропозиціями (при цьому обов'язковим є входження заголовка і першої пропозиції). Після цього автоматично формується гіпертекстове представлення дайджесту, його змісту і гіперпосилання на вихідні документи у вхідному інформаційному масиві. При цьому важливо те, що сформований дайджест, який можна розглядати як самостійний документ, має гіпертекстові посилання на документи-першоджерела в Інтернеті. Для перегляду також доступний весь вхідний тематичний інформаційний масив. Наведена вище процедура забезпечує формування дайджесту, що відбиває основні тенденції, представлені у вхідному інформаційному потоці. Разом з тим має сенс формування дайджесту, який відбиває поряд з головною темою декілька інших значущих тенденцій, не врахованих у дайджестах першого типу. Дайджест такого типу також можна побудувати, базуючись на технологічних рішеннях, що застосовуються при першому підході, а саме передбачивши в механізмі реалізації наступний алгоритм:
У порівнянні з традиційними підходами впровадження технології контент-моніторингу забезпечує такі переваги, як: одержання оперативних кількісних і якісних аналітичних зрізів у міру появи інформації в Інтернет; включення робочих місць аналітиків у динамічний інформаційний простір; своєчасне надання необхідної профільної інформації; забезпечення цілеспрямованої роботи органів щодо усунення недоліків; конфіденційність. Завдяки зазначеним характеристикам інструментальних засобів роботи з інформаційними потоками та таких факторів їх застосування, як оперативність, повнота і релевантність, а також наявності єдиного захищеного інтерфейсу, технологія контент-моніторингу може сприяти значному підвищенню якості якості інформаційно-аналітичної роботи в інтересах системи державної служби. 1. Дьомін О., Леліков Г., Сороко В. Державна кадрова політика: система роботи з кадрами державної служби // Вісник державної служби в Україні. - 2001. - N 2. - С. 65-84. |
P e к л а м a: [an error occurred while processing this directive][an error occurred while processing this directive] File not found. [an error occurred while processing this directive]