ноябрь 2002 года
| Зарегистрировано
242 бизнес-ресурcа |
| Официальный ежемесячный WWW-Регистр бизнес-ресурсов Украины и зарубежья | |||
| Выпуск
N
7 (13) ноябрь 2002 года |
|||
|
|||
|
КОНТЕНТ-МОНИТОРИНГ CЕТЕВЫХ ИНФОРМАЦИОННЫХ ПОТОКОВ Александр Григорьев, В настоящее время количество новостных сообщений, публикуемых в Интернет во всем мире, превышает 1 000 000 в сутки. Крупнейшие Сетевые интеграторы новостей обрабатывают ежесуточно десятки тысяч сообщений. Ситуация резкого возрастания объемов информационных потоков породила ряд проблем: непропорциональный рост информационного шума ввиду слабой структурированности информации; многократное дублирование информации; появление паразитной информации. Вследствие этого традиционные информационно-поисковые системы постепенно стали утрачивать свою актуальность. Охват, обобщение больших динамических информационных массивов, непрерывно генерируемых в Сети, требует качественно новых подходов. Возникла необходимость создания методов мониторинга информационных ресурсов, тесно связанных с методологией контент-анализа. Контент-мониторинг - это содержательный анализ информационных потоков с целью получения необходимых качественных и количественных срезов, который, в отличие от контент-анализа, производится непрерывно во времени. Система контент-мониторинга базируется на статистических методах контент-анализа, которые в последнее время получили большое развитие во всем мире, и, в частности, в России. Так, наиболее интересными сегодня являются проекты М. Г. Крейнеса "Ключи от текста", проект "Оружие аналитика" компании "Инвента", проект ╚ВААЛ╩ и многие другие. В настоящее время разработанная в ИЦ "ЭЛВИСТИ" система контент-мониторинга обеспечивает автоматизированную подготовку нескольких видов отчетов, в состав которых входят таблицы взаимосвязей понятий и гистограммы распределения понятий. Эти отчеты позволяют анализировать отображение процессов реальной жизни в Сетевых публикациях в количественных срезах, а также выявлять тенденции к взаимосвязям отдельных понятий. 3. Таблицы взаимосвязей понятий Построение таблиц взаимосвязей и гистограмм распределения весовых значений понятий базируется на языковых средствах информационно-поисковой системы (ИПС), а также методах статистики и кластерного анализа. Таблица взаимосвязей понятий, которая строится как статистический отчет, отражающий близость (совместную встречаемость в публикациях) отдельных понятий реального мира, √ это симметричная матрица A={aij}, где aij√ коэффициенты взаимосвязи пары понятий i и j. Коэффициент aii соответствует количеству документов входного информационного потока, которые включают понятие (термины или словосочетания, представленные на языке запросов, соответствующие понятию) i, а коэффициент aij √ количеству документов во входном потоке, которые одновременно соответствуют понятиям i и j. При этом для переупорядочения понятий с целью выявления блоков - множеств наиболее взаимосвязанных понятий - применяется алгоритм кластерного анализа. Например, для выделения двух таких блоков необходимо выделить два понятия-полюса (соответствующих, например, индексам k и l), наиболее тесно связанных с другими понятиями, но наименее связанных между собой. Формально эти условия можно записать таким образом: S aik - akk --> max S ail - all --> max akl --> min, k =\= l Еще одна базовая процедура системы контент-мониторинга - это автоматическое формирование дайджестов. Для дайджеста отбираются документы, в которых наиболее явно отражены тенденции всего входного потока. Такие дайджесты, следовательно, должны в наибольшей степени соответствовать информационным потребностям пользователя, по запросу которого формируется этот входной информационный поток. Для формирования дайджестов используются статистические алгоритмы, основанные на ╚весовом╩ частотном подходе. На первом этапе формирования дайджеста на основании слов, входящих во входной информационный поток, строится словарь системы. При этом каждому из слов приписывается некоторый весовой коэффициент, который определяется как результат учета нескольких составляющих: частоты встречаемости, тематического словаря, определяемого тематикой входного информационного потока, ╚плюс-словаря╩, включающего наиболее важную лексику общего назначения. Для формирования дайджестов с начала выполняется выделение всех слов входного потока документов и построение из них последовательного словарного массива. Затем выполняется нормализация слов с помощью средств автоматического морфологического анализа. После этого все слова словарного массива сортируются и им приписываются веса √ частоты встречаемости. Следующим шагом происходит удаление из словарного массива незначащих слов. Для этого используются специальные программные средства, основанные на использовании "стоп-словаря". В соответствии с критерием (запросом пользователя) на формирование входного потока происходит выбор тематического словаря и последующая корректировка словарного массива с учетом тематического словаря √ т.е. корректировка веса отдельных слов, входящих в тематический словарь. По такому же алгоритму происходит корректировка словарного массива с учетом "плюс-словаря". Последний шаг формирования словаря системы заключается в выборе N (например, N=200) самых весомых слов из словарного массива. Выбор исходных документов для построения дайджеста осуществляется также с учетом их ╚весов╩. Вес каждого документа определяется как нормированная по длине документа сумма весов отдельных слов, входящих в этот документ. Этап выбора документов для дайджеста состоит из таких шагов, как определение веса каждого документа, сортировка входного потока документов по весам, определение смысловых дублей документов по статистическому критерию, отбрасывание документов, непригодных для построения дайджестов (с помощью таблиц ╚стоп-адресов╩ и ╚недопустимых типов документов╩), а также статистически определяемых дублей. Последний шаг этапа выбора документов для формирования дайджеста заключается в выборе М (например, M=10) самых весомых документов из отсортированного и отфильтрованного на предыдущих шагах массива. Статистический алгоритм определения дублирующихся документов из входного потока заключается в определении цепочек ключевых слов и частот их встречаемости для отдельных документов и последующем сравнении между собой этих цепочек слов для всех документов входного потока. В существующей реализации настраивается количество ключевых слов в цепочке и коэффициент близости этих цепочек. Последний этап формирования дайджеста заключается в выделении из М отобранных документов самых значимых предложений и построение из них непосредственно текста дайджеста. Для этого по каждому из М отобранных документов строится словарь, который корректируется по плюс-словарю и тематическому словарю, точно так же, как и весь словарь системы. Затем отбрасываются предложения, не удовлетворяющие эмпирически определяемым семантическим правилам, и взвешиваются все оставшиеся предложения. Каждый из М отобранных на предыдущем этапе документов присутствует в дайджесте не более чем К наиболее весомыми предложениями (при этом обязательно вхождение заглавия и первого предложения). После этого автоматически формируется гипертекстовое представление дайджеста, его содержания и гипер-ссылки на исходные документы во входном информационном массиве. При этом важно то, что формируемый дайджест, который можно рассматривать как самостоятельный документ, обладает гипертекстовыми ссылками на документы-первоисточники в Интернет. Для просмотра также доступен весь входной тематический информационный массив. Приведенная выше процедура обеспечивает формирование дайджеста, отражающего основные тенденции, представленные во входном информационном потоке. Вместе с тем имеет смысл формирование многоаспектного дайджеста, отражающего наряду с главной тенденцией несколько других значимых тенденций, игнорируемых в дайджестах первого типа. Дайджест такого типа также можно построить, базируясь на технологических решениях, применяемых при первом подходе, в результате реализации следующего алгоритма: 5. Пример реализации и результаты работы системы Система контент-мониторинга была использована для получения информационных срезов по тематике ╚Зерно╩. Для этой задачи использовался входной поток объемом свыше 250000 документов, полученный системой InfoStream из сети Интернет за 50 суток из более 250 источников. На первом этапе был сформирован тематический информационный канал (документальный файл) по заданной тематике, для чего системой был обработан следующий запрос: Объем полученного информационного канала составил 370 документов, которые были автоматически классифицированы, и из которых средствами системы InfoReS была создана база данных. Ниже приведены созданные экспертами ИЦ ╚ЭЛВИСТИ╩ рубрики классификатора и соответствующие им запросы:
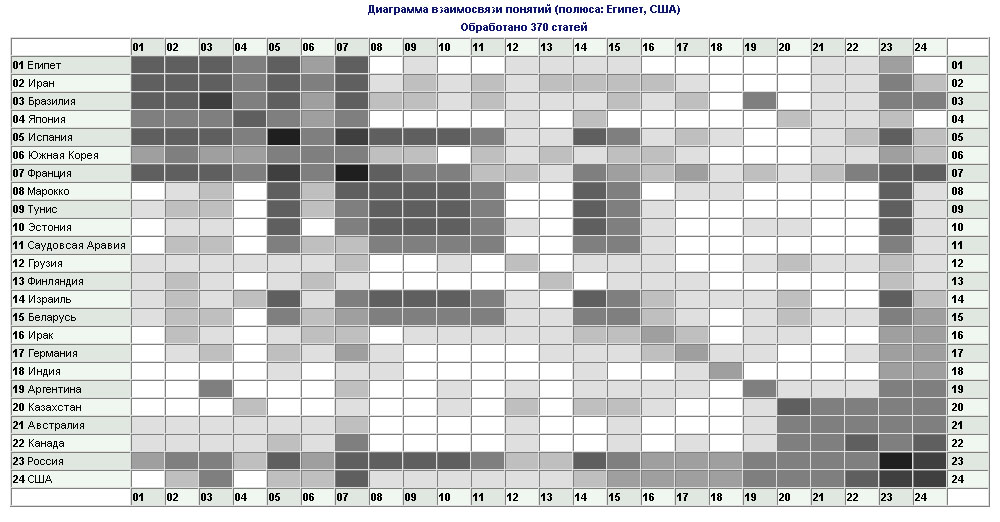
После создания базы данных, отобранные в тематический информационный канал запросы стали доступными для диалогового поиска и просмотра. Кроме того, на основе проведенной автоматической рубрикации была построена таблица взаимосвязей рубрик (понятий), определяемых запросами (Рис. 1). Диагональная часть таблицы взаимосвязей понятий является основой построения гистограммы встречаемости понятий (количество документов по каждому из понятий указано в скобках на гистограмме). Каждая ячейка таблицы взаимосвязей понятий для наглядности закрашивается оттенком серого цвета. Интенсивность закраски зависит от количества документов, соответствующих одновременно двум выбранным понятиям (по вертикали и горизонтали). Кроме того, каждая ячейка данной таблицы служит гиперссылкой на перечень документов, соответствующих выбранным понятиям. Средства автоматической кластеризации понятий позволяют выбрать наиболее взаимосвязанные понятия. В демонстрационном примере сформировалось два явно выраженных блока - автоматически сгруппировались страны экспортеры и импортеры зерна. Сформированный тематический информационный канал использовался для построения средствами системы контент-мониторинга электронного дайджеста по теме ╚Зерно╩ (Рис. 2). Администратором был задан объем дайджеста в 10 документов, по 3 абзаца в каждом. При этом заголовок каждого документа содержит гипер-ссылку на соответствующий документ в полнотекстовой базе данных тематического информационного канала. |
По сравнению с традиционными подходами внедрение технологии контент-мониторинга обеспечивает такие преимущества: получение оперативных количественных и качественных аналитических срезов;включение рабочих мест сотрудников-аналитиков в динамическое информационное пространство, своевременное предоставление необходимой профильной информации; обеспечение целенаправленной работы сотрудников, устранение факторов отвлечения внимания, присущих Интернет; защита данных, конфиденциальность. Благодаря таким характеристикам используемых инструментальных средств работы с информационными потоками, как оперативность, полнота и релевантность, а также наличию единого защищенного интерфейса, технология контент-мониторинга может способствовать значительному повышению эффективности и качества информационно-аналитической работы. |