КОНЦЕПЦІЯ АНОТОВАНОГО ПОШУКУ
С.М. Брайчевський, Д.В. Ланде
Представлено новий підхід до організації інформаційного пошуку в надвеликих базах даних, породжуваних розвитком сучасних мережних технологій. Основна ідея концепції полягає в підвищенні рівня пертинентності відгуків інформаційно-пошукової системи за рахунок деякого зниження рівня повноти пошуку. Технологічною основою даної концепції служить інструментарій автоматичного реферування текстів, а також методи кластерного аналізу, що забезпечують автоматичне групування документів. Пропонується методика скорочення реального обсягу пошукового простору.
Вступ
Парадокс у розвитку мережних пошукових систем полягає в тому, що їхнє технічне вдосконалювання в рамках традиційної парадигми неминуче приводить до лавиноподібного зростання баз даних, і відповідно, обсягів релевантних вибірок, які кінцевий споживач у підсумку не в змозі обробити [1]. Сучасні технології дозволяють здійснювати витончені операції над даними, але чим ефективніше вони застосовуються, тим менш "їстівним" виявляється результат. Схоже, що технічний прогрес у цьому випадку не поліпшує, а погіршує ситуацію.
Існуючі інформаційно-пошукові системи первісно проектувалися для забезпечення релевантності вибірки в поєднанні з вимогою повноти пошуку, але саме в цьому і полягає їхній головний недолік. Неконтрольований рівень пертинентності вибірки при цьому різко знижує ймовірність одержання користувачем саме тієї інформації, що йому потрібна.
Причини надлишковості результатів стандартного інформаційного пошуку можуть бути розділені на дві якісно різні категорії: дублювання інформації та інформаційна невідповідність. Істотним є те, що приналежність документа до числа дублів носить цілком об'єктивний характер і може визначатися автоматично на підставі формальних критеріїв. Навпаки, інформаційна невідповідність породжує проблеми суто суб'єктивного характеру, тому що машина не в змозі визначити, чи відповідає зміст даного документа інформаційним потребам даного користувача.
Тому стає ясно, що пошукові технології повинні бути розширені за рахунок застосування додаткових семантичних засобів, що дозволяють або скоротити розрив між рівнями релевантності й пертинентності, або якось його компенсувати.
Модифікація задачі пошуку
Найбільш перспективним з існуючих сьогодні напрямків, безсумнівно, є автоматичне групування результатів пошуку [2], тобто розбивка релевантної вибірки документів на кластери. Разом з тим вона не вирішує проблему по суті, оскільки хоча й допомагає орієнтуватися в результатах пошуку, але аж ніяк не приводить до скорочення їхніх обсягів. Головна перевага автоматичного групування полягає в ієрархічній організації результатів пошуку, що дозволяє на першому етапі мати справу з обмеженим набором кластерів, а потім уже переходити до складу того або іншого кластера. Складність, однак, полягає в тому, що розбивка вибірки на групи здійснюється на підставі близькості документів, що розуміється формально. Ця обставина, природно, приводить до того, що кінцевий ефект залежить від багатьох, у тому числі й випадкових, факторів і носить явно неконтрольований характер.
Особливої актуальності набувають підходи, що дозволяють переформулювати задачу пошуку таким чином, щоб його результати дійсно могли бути без зусиль сприйняті користувачем.
Одним з головних принципів, покладених в основу більш адекватних підходів, на наш погляд, є відмова від вимоги повноти пошуку.
Цілком вартою виглядає постановка задачі попередньої обробки початкової сукупності документів, що має на меті сформувати деякий ефективний набір даних, що відбиває в розумному наближенні її зміст і призначений для подальшого пошуку по ньому.
Сама по собі така постановка задачі аж ніяк не є новою: вона широко й успішно застосовується в сфері автоматичного реферування документальних потоків. Саме продуктивність подібної методики в суміжній області й змушує нас уважно придивитися до її можливостей стосовно до інформаційного пошуку.
Анотований пошук
У технологічному плані пропонується реалізація принципу попередньої обробки текстового матеріалу за допомогою методик, характерних для іншої області інформаційних технологій, а саме контент-аналізу. Така обробка передбачає автоматичне виділення найбільш значимої інформації і відсівання "сміття", що дозволить споживачеві працювати з наборами даних, досить обмеженими за обсягом, і, при правильній організації, може істотно підвищити рівень пертинентності результатів пошуку. Концепція також передбачає свого роду кластеризацію, однак розподілу по групах підлягає не тільки релевантна вибірка, але й вихідний набір документів, у якому ведеться пошук.
У рамках концепції використовуються терміни "анотований пошук" й "анотована база даних", оскільки, як буде видно нижче, основні алгоритми пошуку і структура бази даних нагадують ті, які використовуються при автоматичному реферуванні.
Центральна ідея пропонованої концепції полягає в тому, що релевантність документа варто визначати стосовно деякого його інформаційного образа. Причому останній повинен бути побудований саме так, щоб відбивати основний зміст документа. Такий образ документа (або групи документів) у рамках даної концепції називається анотацією.
Структура і форма анотації не мають принципового значення, але в кожному разі вона повинна містити впорядкований набір термінів та/або фраз, що входять до складу відповідного документа і мають певний рівень вагових значень. Вага може характеризувати значимість термінів або фраз у документі і може визначатися різними методами залежно від властивостей предметної області та поставленої задачі. Крім того, оскільки споживача в остаточному підсумку цікавлять тексти документів, сукупність анотацій повинна бути доповнена системою відповідних посилань. Разом вони утворять деякий набір метаданих, що повинен бути включений у загальну індексну систему бази даних.
На рисунку наведено схему функціонування анотованої бази даних.
Технологічна реалізація анотованого пошуку
Як інформаційно-технологічна основа розглядається база даних традиційної інформаційно-пошукової системи із властивою їй структурою, включаючи, наприклад, індексні, інверсні, словникові таблиці тощо.
Створення анотованої бази даних має на увазі створення бази даних пошукових образів первинних документів та їх кластеризацію, тобто автоматичне формування груп документів із близькими за деякими критеріями пошуковими образами (ПОД).
При формуванні анотованої бази даних найважливіший аспект - формування бази даних анотацій, тобто пошукових образів кластерів (ПОК), які, власне, і будуть використовуватися в процесі пошуку. Природно, ця база даних пов'язана з базою даних кластерів, кожен запис якої відповідає певному кластеру та включає, крім усього іншого, його опис (виконаний методами автоматичного реферування).
Методи автоматичного реферування (а точніше квазіреферування, заснованого на переважному використанні методів статистичного аналізу текстів) використовуються, з одного боку, для створення ПОД, а з іншого боку і описів, доступних користувачам.
Задача повнотекстового пошуку по надвеликих текстових масивах може виявитися неефективною, наприклад, в романі "Війна і мир" Л.Толстого можна знайти більшість лексем російської мови. Пошук по анотованих текстах у таких випадках вирішує проблему точності. Тобто, замість пошуку по повних текстах виявляється доцільним проводити пошук по анотаціях - пошукових образах документів. Хоча квазіреферат часто для великих текстів виявляється утворенням, що лише віддалено нагадує вихідний текст, який при цьому найчастіше не сприймається людиною, але саме як пошуковий образ документів, що містить зважені ключові слова і фрази, він може приводити до цілком адекватних результатів при повнотекстовому пошуку.
Квазіреферат у більшості відомих систем будується з текстових фрагментів, що мають найбільші вагові значення. Загальна вага текстового блоку на цьому етапі визначається за формулою [3]:
Weight = Location + KeyPhrase + StatTerm
Коефіцієнт Location визначається розташуванням блоку у вихідному тексті та залежить від того, де з'являється даний фрагмент - на початку, у середині або наприкінці, а також чи використовується він у ключових розділах тексту, наприклад, у висновку.
Ключові фрази (KeyPhrase) являють собою конструкції-маркери, що резюмують, типу "на закінчення", "у даній статті", "відповідно до результатів аналізу" і т.п. Ваговий коефіцієнт ключової фрази може залежати також від оцінного терміна, наприклад, "відмінний".
Статистична вага текстового блоку (StatTerm) обчислюється як нормована за довжиною цього блоку сума ваг термінів, що входять у нього - слів і словосполучень. Після виявлення певної, заданої коефіцієнтом необхідного стиснення, кількості текстових блоків з найвищими ваговими коефіцієнтами, вони об'єднуються для побудови квазіреферата.
Слід зазначити, що не тільки анотації у вигляді ПОК, але і описи окремих елементів у базі даних анотацій, доступної на етапі пошуку, створюються на основі засобів автоматичного реферування, які на цьому етапі не враховують інформаційних потреб користувачів, виражених пошуковими приписаннями (запитами).
У рамках даної концепції передбачається використання методів квазіреферування, перевага яких полягає в простоті реалізації.
При звертанні користувачів до бази даних передбачається така процедура: запит користувача відпрацьовується за базою даних анотацій, після чого пошуковою процедурою виконується формування набору релевантних кластерів, найменування та описи яких, з одного боку, можуть пред'являтися користувачам (якщо їх кількість не перевищує заданої заздалегідь), а, з іншого боку, якщо кількість результатів пошуку (кластерів) перевищує це значення, то результати пошуку автоматично групуються, утворюючи суперкластери, перелік яких і пред'являється користувачеві.
Природно, в останньому випадку користувачеві пред'являються назви суперкластерів та їхні описи - реферати, складені автоматично вже з урахуванням запитів користувачів. Тобто, вага текстових фрагментів у цьому випадку описується уточненою формулою:
Weight = Location + KeyPhrase + StatTerm + UserPref
Коефіцієнт UserPref - переваги, що надає користувач, залежать від того, наскільки слова і словосполучення, наведені в його запиті, присутні в даному фрагменті.
Представлення результатів пошуку може здійснюватися різними способами, залежно від особливостей предметної області, структури документальної бази даних, характеру інформаційних потреб користувачів тощо. Відзначимо лише, що самі анотації, як ми вже відзначали вище, є пошуковими образами - внутрішніми елементами системи і користувачеві у вихідному виді не пред'являються. Тому припускається, що з метою адекватного відображення результатів пошуку кожен побудований кластер забезпечується описом, що також будується автоматично та видається користувачеві як "етикетка" кластера, яка, на відміну від анотації, являє собою зв'язний текст. Далі користувач, якщо побажає, може переглянути всі документи, що входять до складу даного кластера.
Припускається, що при такій організації пошуку релевантними виявляться лише ті документи, для яких пошукові терміни запиту користувача є інформаційно-значимими. Це досягається вже в силу тієї обставини, що самі анотації за своєю природою мають саме таку властивість. Наявність у них винятково термінів або фраз із досить великими ваговими значеннями перешкоджає попаданню в релевантну вибірку документів, в яких пошукові терміни присутні у вигляді інформаційного шуму.
Закінчення
Слід зазначити, що наведена модель у цей час ще не реалізована повністю у вигляді програмно-технологічного забезпечення, однак окремі елементи вже створені й пройшли досить велику апробацію. Залишилася справа за малим - запустити цю модель на реальних надвеликих обсягах даних. До реалізованих елементів належать: традиційні повнотекстові інформаційно-пошукові системи, включаючи авторську розробку - систему InfoRes; алгоритми автоматичного реферування; механізми кластеризації як статичних, так і динамічних масивів інформації, які знаходять уже сьогодні застосування, наприклад, при виявленні основних сюжетів у системі контент-моніторингу InfoStream; адаптивні інтерфейси уточнення запитів до інформаційно-пошукової системи.
Представлена модель орієнтована на практичну реалізацію і у явному вигляді містить ряд технологічних обмежень, головне з яких пов'язане з тим, що на етапі індексування пошукові образи документів створюються без урахування запитів користувачів. ПОД не є повною копією документів, тому заздалегідь не можуть бути враховані всі нюанси інформаційних потреб користувачів, що може позначитися не тільки на повноті, але й на релевантності. Згладити названу проблему можуть лише витончені інтелектуальні алгоритми автоматичного реферування.
Разом з тим пропонована організація пошуку дозволить вирішити наступні важливі задачі:
- автоматичне групування документів і тим самим скорочення реального обсягу простору пошуку;
- пред'явлення користувачеві винятково інформаційно значимих документів;
- при необхідності виключення дублів з результатів пошуку при збереженні їх у самій базі даних.
Згадаємо, що середня довжина запиту до пошукової системи в Інтернет не перевищує 2-3 слів, можливо в тому числі і через це основні проблеми користувача зводяться до вирішення проблеми релевантності-повноти, і, в остаточному рахунку, пертинентності видачі. Очевидно, пропонована система організації пошуку дозволить істотно підвищити його привабливість із погляду "середньостатистичного" користувача.
Через зростаючі обсяги інформації пошукові системи вже сьогодні не в змозі надати в розпорядження все те, що потрібно користувачеві з наявного в Інтернет, тому реалізація даної концепції навіть на першому етапі пошуку дасть йому відносно невелику вибірку, подбавши про те, щоб вона була змістовною.
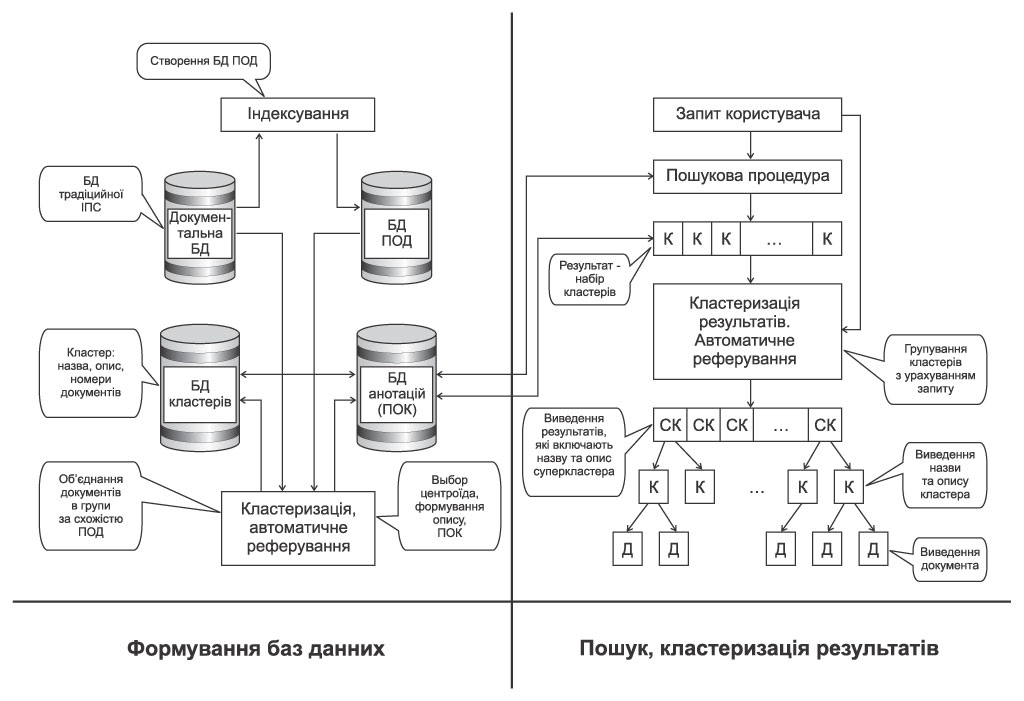
Рисунок. Архітектура і модель функціонування анотованої бази даних
Список літератури
- Современные информационные потоки: Актуальная проблематика / Брайчевский═С.М., Ландэ Д.В. // "Научно-техническая информация", серия 1, ╧ 11. - 2005. - С. 21-33.
- Григорьев А.Н., Ландэ Д.В. Адаптивный интерфейс уточнения запросов к системе контент-мониторинга InfoStream//Труды Международного семинара "Диалог'2005". - 2005. - С. 109-111.
- Ландэ Д.В. Поиск знаний в Internet. Профессиональная работа. - М.: "Вильямс", 2005. - 272 с.
